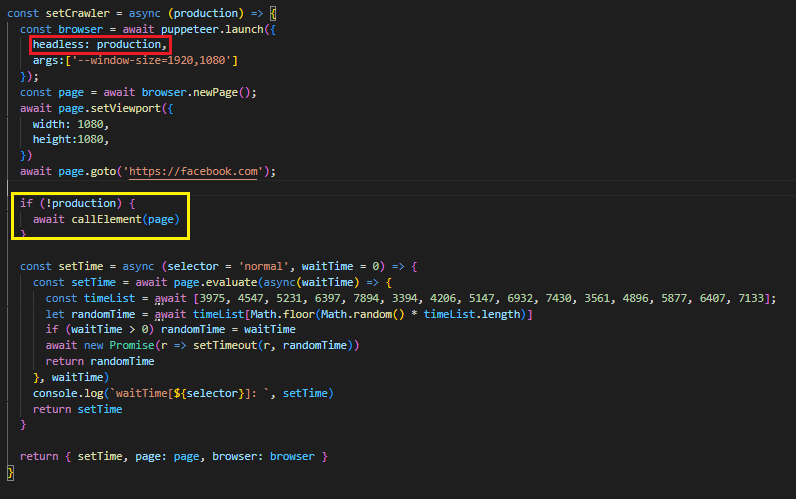
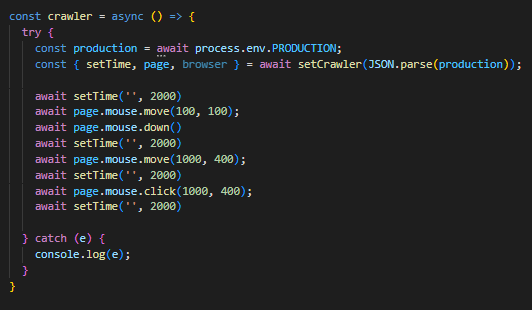
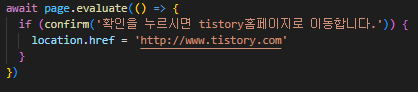
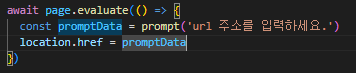
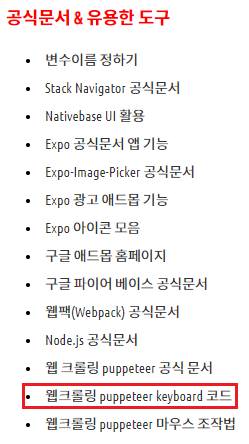
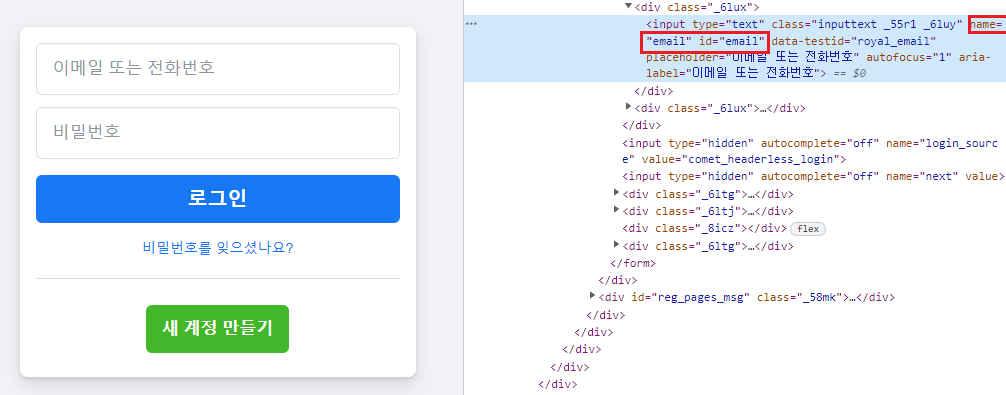
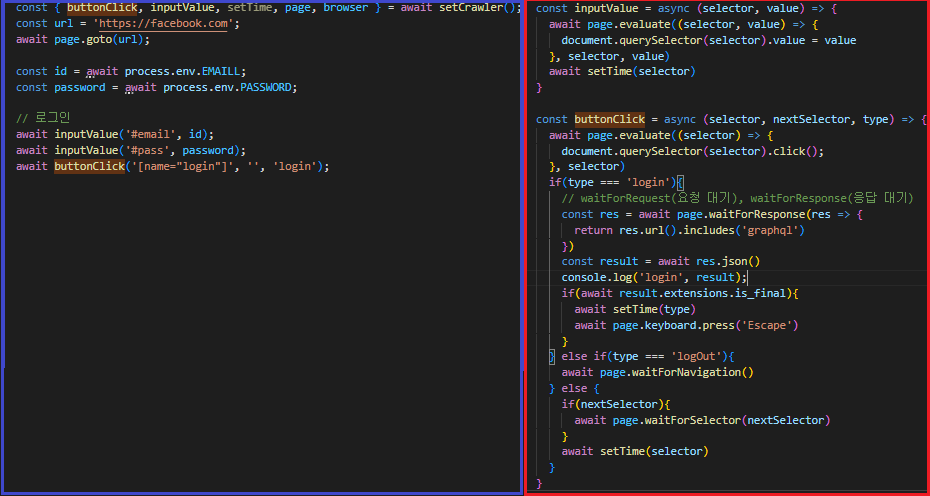
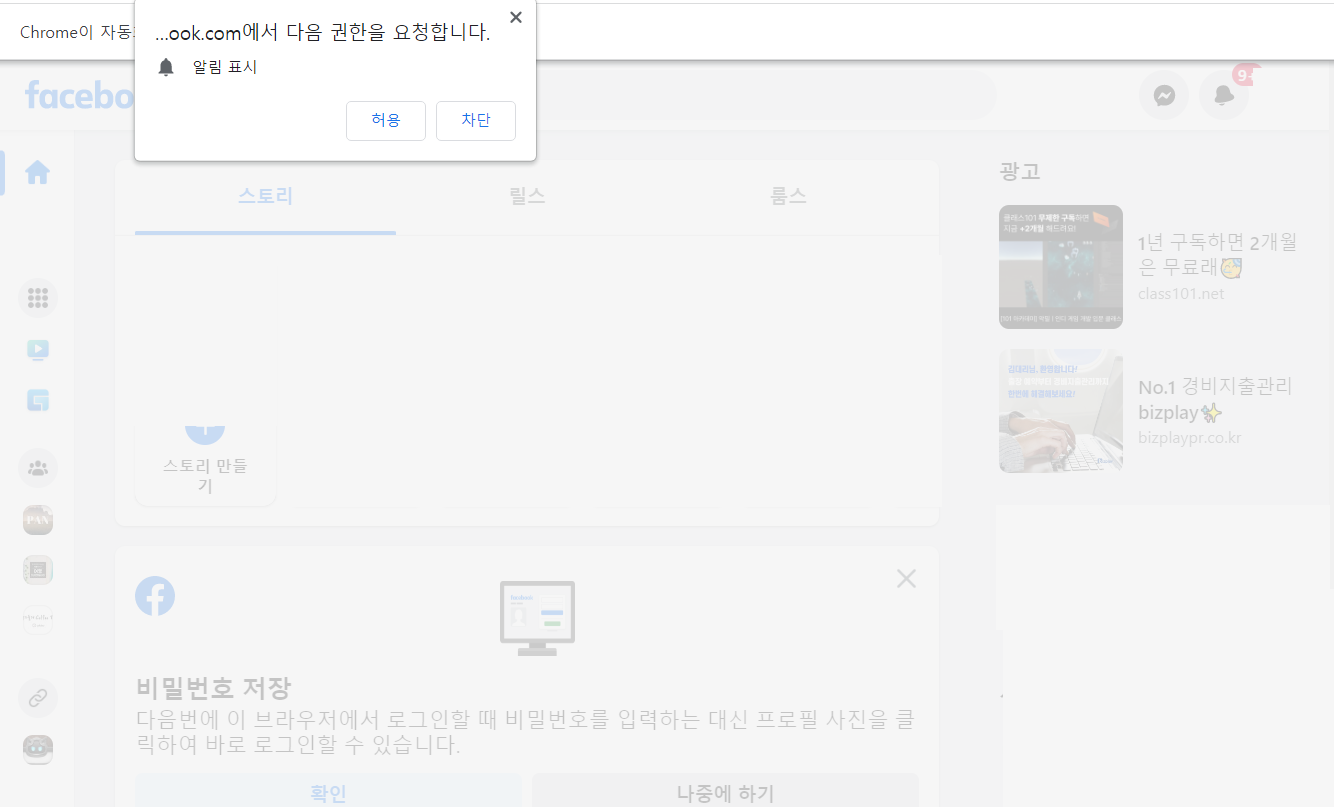
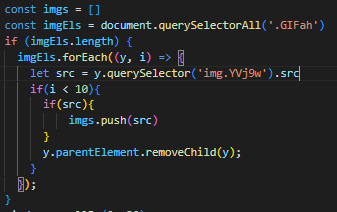
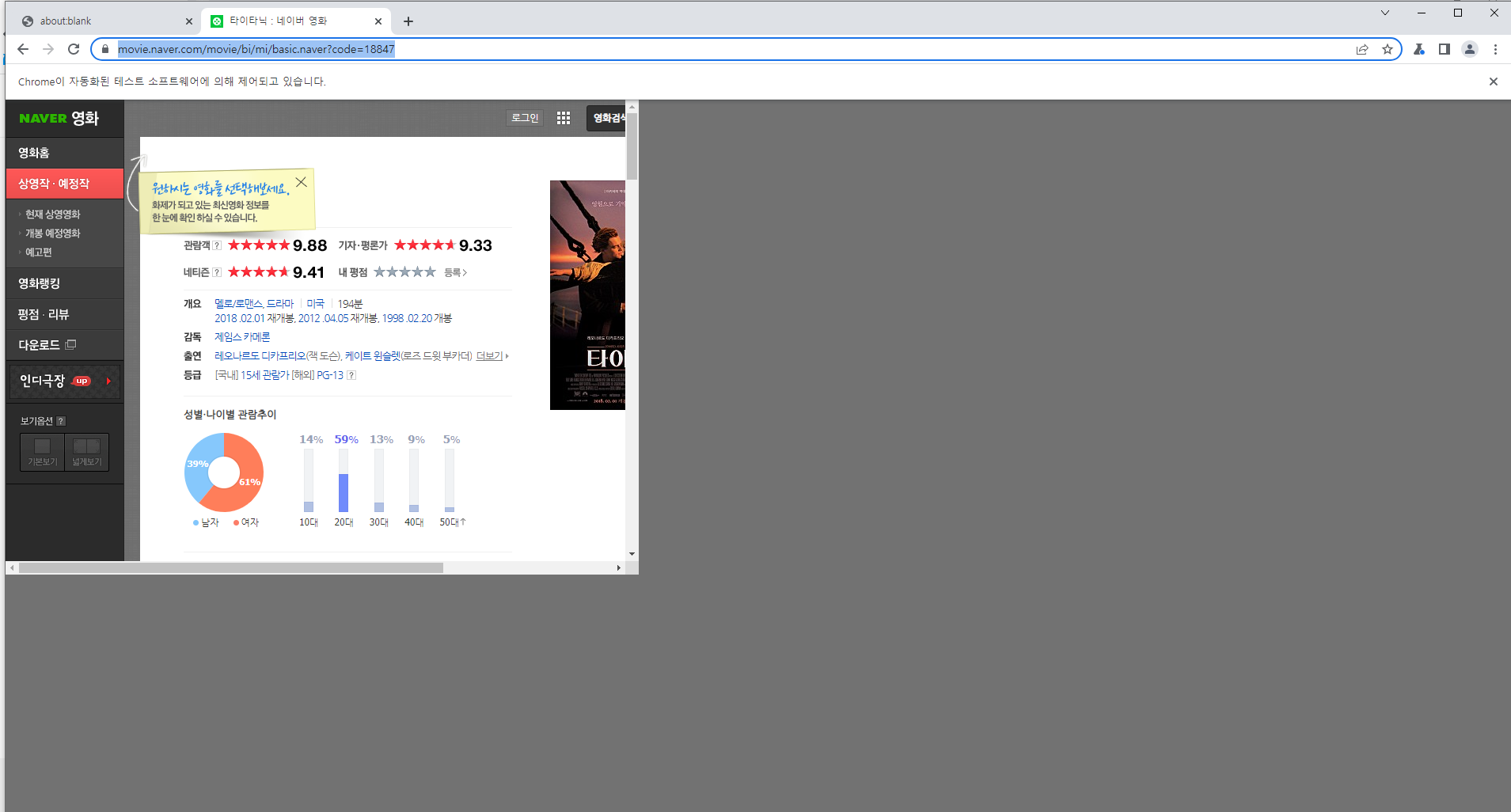
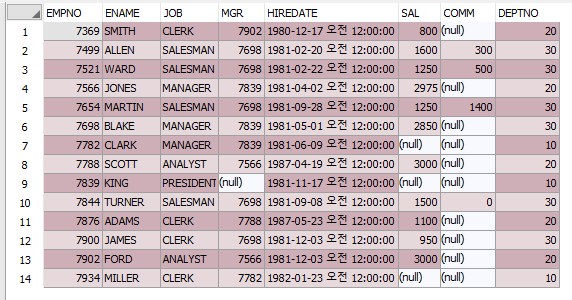
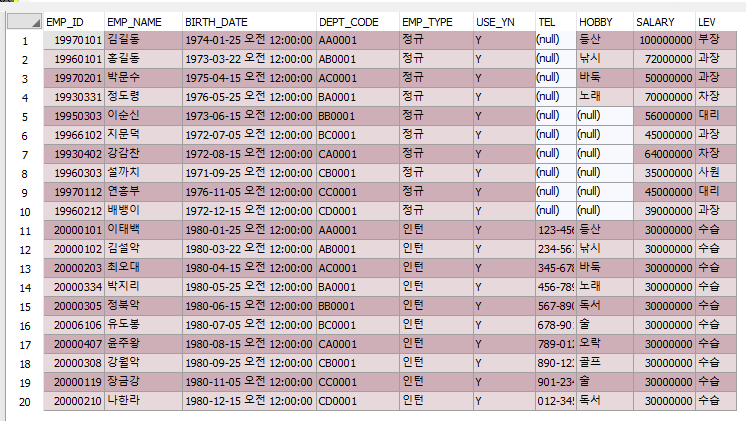
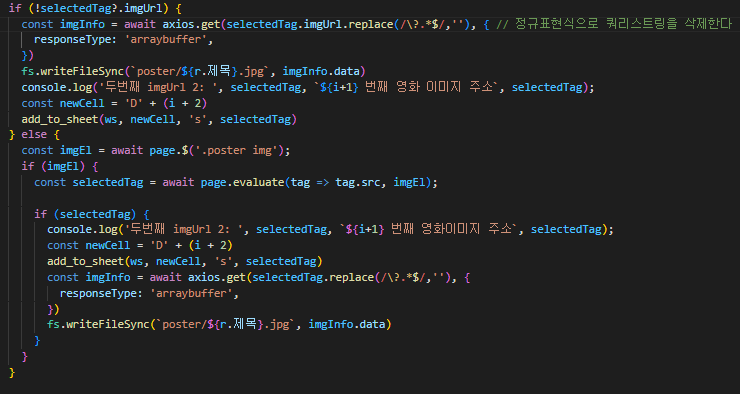
SELECT deptno, coount(*) AS CNT FROM EMP GROUP BY deptno;
하나의 행으로 출력하는 과정을 알아보도록 하겠습니다
아래의 코드를 분석해 봅시다
select deptno,
case when deptno=10 then 1 else 0 end as deptno_10,
case when deptno=20 then 1 else 0 end as deptno_20,
case when deptno=30 then 1 else 0 end as deptno_30
from emp
order by 1
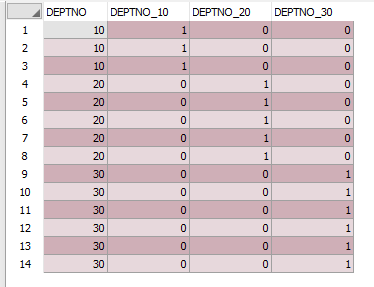
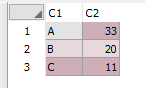
위의 코드로 아래와 같이 조회되는 것을 확인할 수 있습니다
위의 DEPTNO 컬럼은 가독성을 위한 값이니 참고하시기 바랍니다.
CASE WHEN THEN ELSE END를 활용해서 한 컬럼에 대해서 값을 출력합니다
그 값은 간단합니다 DEPTNO가 10이면 1을 주고 나머지는 0을 부여하게 됩니다.
그리고 두 번째 컬럼은 DEPTNO가 20, 세번째 컬럼은 DEPTNO가 30으로
아래의 데이터가 조회됩니다 그러나 아직은 조금 미흡합니다
아직 행이 하나가 아니기 때문이지요
그럼 조금 수정해보겠습니다
case문으로 쿼리 조회
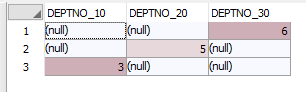
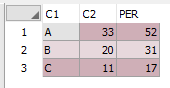
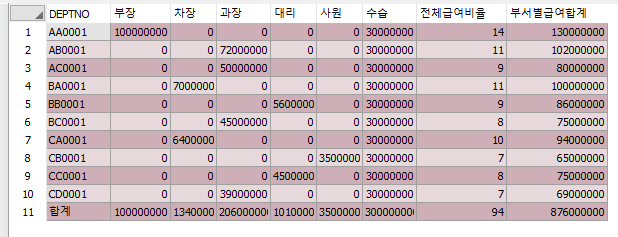
아래의 코드로 합계결과 값은 하나의 행으로 반환하였습니다
위의 결과 값에서 집계 함수 SUM을 사용하여 각 DEPTNO의 발생 횟수를 계산합니다
select sum(case when deptno=10 then 1 else 0 end) as deptno_10,
sum(case when deptno=20 then 1 else 0 end) as deptno_20,
sum(case when deptno=30 then 1 else 0 end) as deptno_30
from EMP;
아래와 같이 최종 결과가 출력됩니다
최종 결과
하지만 아직 조금 부족합니다 그 이유는 한 테이블에서 CASE문을 전체를 적용해서
시스템상 성능 부하가 올 수 있습니다 그리고 단순히 CASE 표현식을 합산하는 방법을 이기 때문입니다
지금은 데이터가 많이 없기 때문에 이 같은 방법을 해도 문제가 없지만 데이터가 몇만 건씩 넘어간다면
문제가 발생할 것입니다
다른 방법을 알아보도록 하겠습니다
select case when deptno=10 then empcount else null end as deptno_10,
case when deptno=20 then empcount else null enD as deptno_20,
case when deptno=30 then empcount else null end as deptno_30
from (
select deptno, count(*) as empcount
from emp
group by deptno
) x;
아래의 코드를 자세히 보시면
처음에 COUNT 함수를 사용했던 것을 기억하실 것입니다
그 쿼리를 인라인 뷰로 사용하여 부서당 사원수를 생성합니다
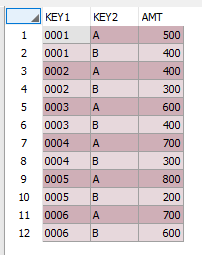
그럼 그 결과 값은 아래와 같이 출력되는 것을 확인할 수 있습니다
이 방법은 인라인 뷰로 먼저 생성된 데이터가 3개의 행이므로
CASE문 실행할 경우 전체 행을 읽지 않고 3개의 행만으로
결과를 출력할 수 있습니다
인라인 뷰 활용 예
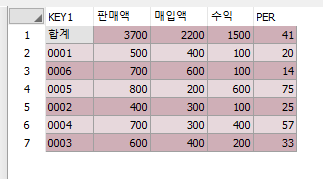
그런 다음 MAX 함수로 열을 하나의 행으로 축소를 합니다
아래의 코드를 확인해 봅시다
select max(case when deptno=10 then empcount else null end) as new_deptno_10,
max(case when deptno=20 then empcount else null end) as new_deptno_20,
max(case when deptno=30 then empcount else null end) as new_deptno_30
from (
select deptno, count(*) as empcount
from emp
group by deptno
) x;
HP라는 제품은 너무 많은 등급을 가지고 있어 제품별로 분석하기를 원하고, ‘LD’라는 제품은 등급의 수가 적고 중요하므로 등급별로 분석하기를 원하며, ‘PP’라는 제품은 다양한 등급을 가지고 있으나 ‘P530C’라는 등급은 전략적으로 관리하고자 하여 등급별로 분석하고, 나머지는 기타로 모아주기를 원한다고 생각하자
CSV 파일을 파싱 할 때 주의해야 할 점은 버퍼 파일이기 때문에 인코딩을 해야 하는 것을 잊지 말아야 합니다
// npm 패키지 불러올때 사용하는 require함수입니다
// 또한 node_modules파일에서 경로를 그대로 따라가서 그 함수를 들고온다고 생각하면된다
// 노드서버를 만들어서 배포하는 것이 좋습니다
const parse = require('csv-parse/lib/index.js');
const fs = require('fs'); // 파일시스템 모듈을 불러온다
const csv = fs.readFileSync('csv/data.csv'); // 파일을 불러오는 함수
// 이때 불러오게된 csv에는 버퍼(Buffer)형식이라서 문자열로 변경해주어야한다
// 버퍼는 0,1로 이루어진 컴퓨터 친화적인 데이터이다
csv.toString('utf-8') // toString을 하면서 인코딩을 하는 것은 잊지말자
console.log('result: ', csv.toString('utf-8'));
const records = parse(csv.toString('utf-8'))
records.forEach((movieInfo, i) => {
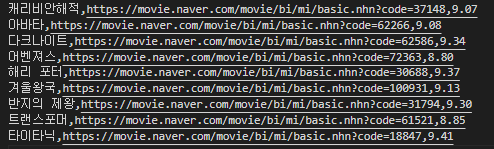
console.log('영화제목: ', movieInfo[0], '*** 영화링크: ', movieInfo[1]);
});
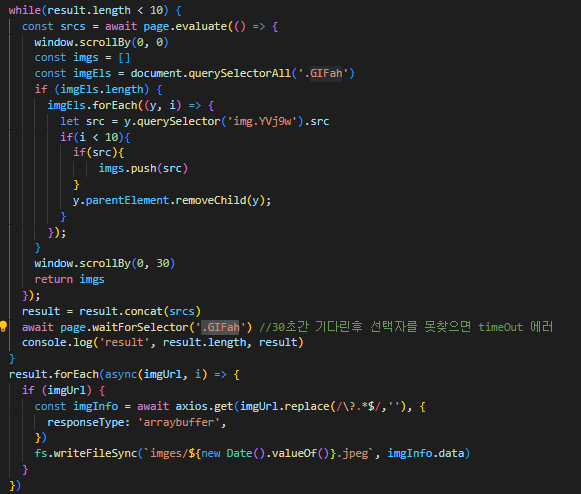
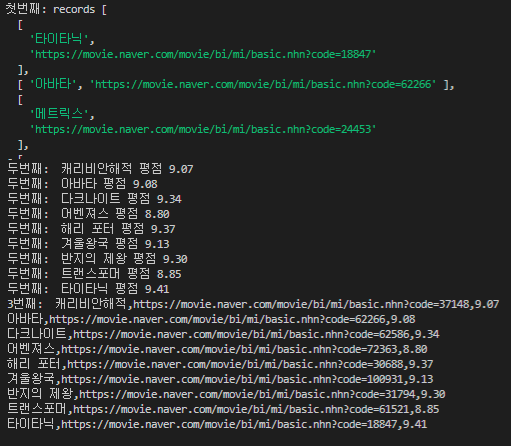
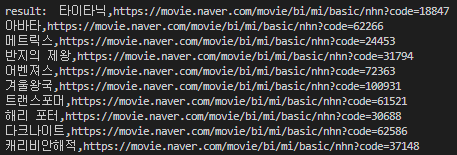
첫 번째 콘솔인 result에 해당하는 값을 확인해보면 아래와 같이 확인할 수 있습니다
아래는 단지 파일을 읽어온 결과 값입니다
csv파일읽은결과
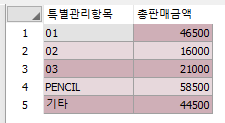
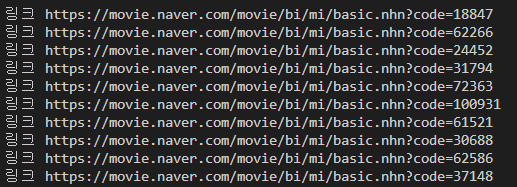
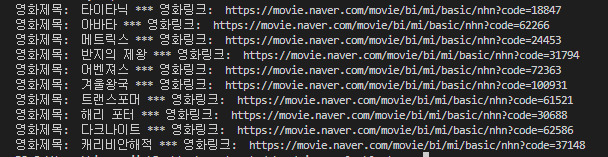
두 번째 CSV 파일을 파싱 한 결과를
영화 제목과 링크로 나누어 보이는 결과 값입니다
아래와 같습니다
csv파일 파싱 결과
이제 데이터를 어떻게 사용해야 할지 감이 잡이시나요?
그럼 다음은 엑셀입니다
반응형
엑셀 파싱 해서 데이터 가져오기
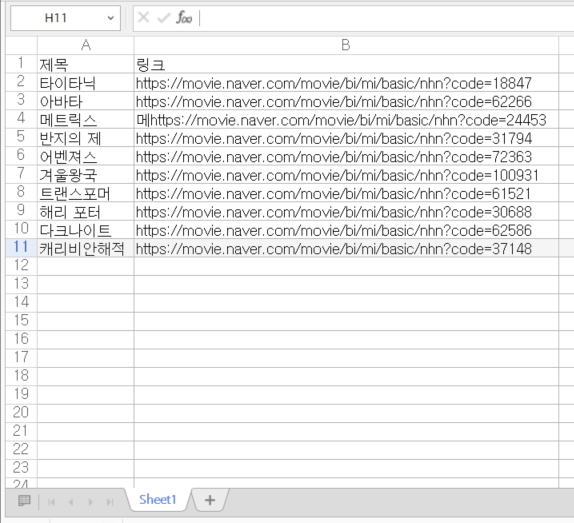
엑셀 파일에 가져올 데이터를 채워서 파일로 준비합니다
엑셀파싱데이터
엑셀 파싱 관련 라이브러리를 추가합니다
엑셀 파싱은 정말 혼자서 만들기 힘드니 라이브러리를 이용하시길 바랍니다
npm i xlsx
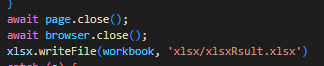
그리고 아래의 코드를 index.js에 작성하여 줍니다
그리고 npm start를 실행하게 합니다
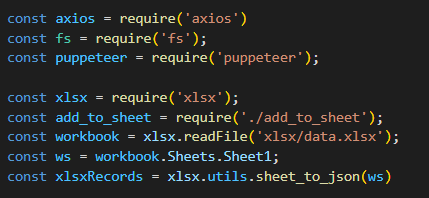
const xlsx = require('xlsx');
const workbook = xlsx.readFile('xlsx/data.xlsx');
console.log('readFile: ', Object.keys(workbook.Sheets))
const ws = workbook.Sheets.Sheet1; // 시트 명(Sheet1)을 뒤에 붙여준다
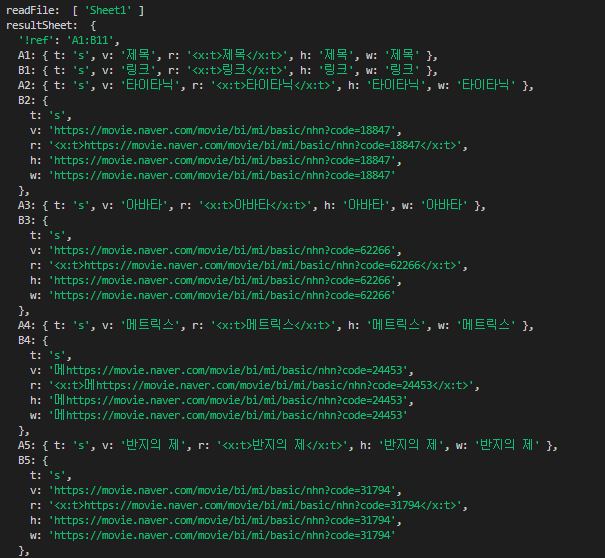
console.log('resultSheet: ', ws)
// .sheet_to_json()함수로 시트에 담긴 데이터를 json파일로 변경해준다
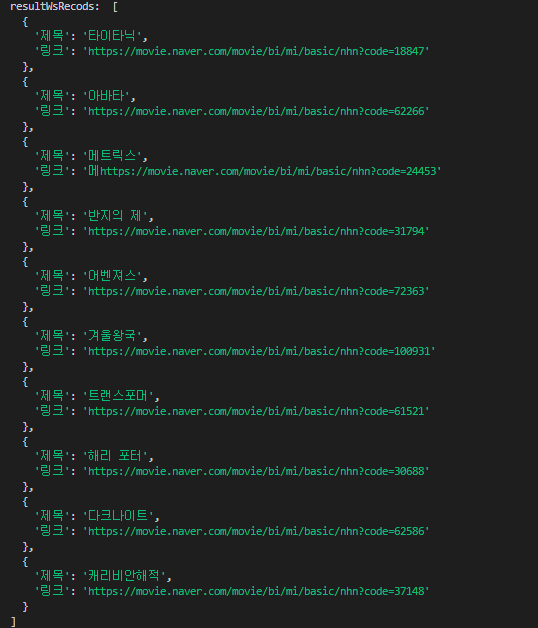
const wsRecods = xlsx.utils.sheet_to_json(ws);
console.log('resultWsRecods: ', wsRecods)
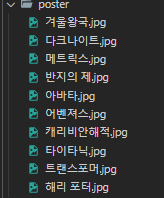
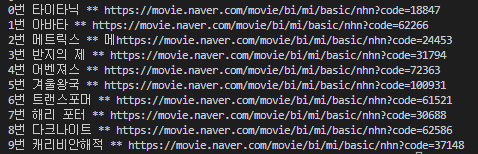
for (const [i, r] of wsRecods.entries()) {
console.log(`${i}번 ${r.제목} ** ${r.링크}`)
}
첫 번째 콘솔에 readFile을 보시면 ['Sheet1']이 들어가 있는 것을 확인할 수 있습니다
그래서 workbooks.Sheet.Sheet1으로 파일을 받아올 수 있게 되는 것입니다
그리고 두 번째 콘솔에 resultSheet를 보시면 엑셀 파일의 데이터가 저장되어있는 것을 확인할 수 있습니다
엑셀의 데이터를 ws라는 변수에 저장해서 xlsx라이브러리를 사용해서 파싱 해서 데이터를 가져옵니다