
이전 포스팅에서 웹크롤링 Puppeteer 및 Promise 활용 방법
Node.js로 웹 크롤링할 경우 Puppeteer를 사용하면 정말 편하게 개발을 할 수 있습니다
evaluate() 함수를 활용하여 잠시 대기시간을 갖거나,
선택자를 지정하여 태그에 대해 접근하여 값을 가져오거나 등
여러 가지 작업을 간편하게 하였습니다
더 자세한 사항을 알고 싶으시다면 아래의 링크를 확인해주세요
2022.08.20 - [IT_Web/Nodejs] - nodejs 웹 크롤링을 Puppeteer 및 Promise 활용 완벽 파헤치고 CSV 파일 쓰기
nodejs 웹 크롤링을 Puppeteer 및 Promise 활용 완벽 파헤치고 CSV파일 쓰기
이전 포스팅에 대하여 이전 포스팅에서는 간단하게 웹 크롤링을 하는 방법을 알아보았습니다 axios와 cheerio를 사용해서 웹 크롤링을 해보았습니다 하지만 axios는 한계가 있습니다 싱글 페이지로
tantangerine.tistory.com
웹크롤링 이미지 다운로드 및 이미지 주소 엑셀에 입력하기
우선 이전 포스팅에서 계속 이어져서 작업을 진행하고있으니
이전 포스팅을 꼭 확인해주세요
아래의 코드를 한번 천천히 살펴보시길 바랍니다
그리고 세부 설명은 아래에서 이미지와 같이 진행하겠습니다
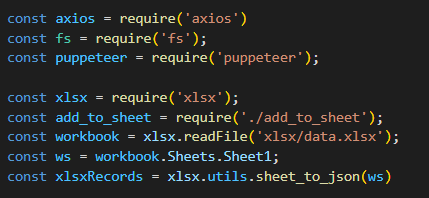
const axios = require('axios')
const fs = require('fs');
const puppeteer = require('puppeteer');
const xlsx = require('xlsx');
const add_to_sheet = require('./add_to_sheet');
const workbook = xlsx.readFile('xlsx/data.xlsx');
const ws = workbook.Sheets.Sheet1;
const xlsxRecords = xlsx.utils.sheet_to_json(ws)
fs.readdir('screenShot', (err) => { // readdir는 비동기로 이벤트 루프 속에서 작동하기 때문에 밑에 함수와는 관계가 없다
if(err) {
console.log('screenShot 폴더가 없어 screenShot 폴더를 생성합니다.')
fs.mkdirSync('screenShot') // 프로그램이 처음 시작될때 한번만 시작할 때는 Sync는 사용해도 된다
}
})
fs.readdir('poster', (err) => {
if(err) {
console.log('poster 폴더가 없어 poster 폴더를 생성합니다.')
fs.mkdirSync('poster')
}
})
const crawler = async () => {
try {
const browser = await puppeteer.launch({headless: false});
console.log('첫번째: records', xlsxRecords)
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36')
add_to_sheet(ws, 'C1', 's', '평점')
add_to_sheet(ws, 'D1', 's', '이미지 주소')
for(const [i, r] of xlsxRecords.entries()) {
await page.goto(r.링크);
console.log('userAgent', await page.evaluate('navigator.userAgent'))
const selectedTag = await page.evaluate(async () => {
let score = ''
let imgUrl = ''
const scoreEl = await document.querySelector('.score.score_left .star_score')
const imgEl = await document.querySelector('.poster img')
if (scoreEl) {
score = scoreEl.textContent;
}
if (imgEl) {
imgUrl = imgEl.src;
}
return { score, imgUrl }
})
if (!selectedTag?.score) {
console.log('두번째 selectedTag 1: ',r.제목, `${i+1} 번째 영화 평점`, parseFloat(selectedTag.score.trim()));
const newCell = 'C' + (i + 2)
add_to_sheet(ws, newCell, 'n', parseFloat(selectedTag.score.trim()))
} else {
const scoreEl = await page.$('.score.score_left .star_score');
if (scoreEl) {
const selectedTag = await page.evaluate(tag => tag.textContent, scoreEl);
if (selectedTag) {
console.log('두번째 score 2: ', parseFloat(selectedTag.trim(), `${i+1} 번째 영화 평점`, parseFloat(selectedTag.trim())))
const newCell = 'C' + (i + 2)
add_to_sheet(ws, newCell, 'n', parseFloat(selectedTag.trim()))
}
}
}
// 이미지 주소로 요청을 받아서 이미지 데이터를 받는다
// 이미지 데이터는 버퍼로 받는다 이buffer가 연속적으로 들어있는 자료구조가 arraybuffer라고 한다
// 이미지 주소를 가져올때는 확인을 필히 해야하며 어떠한 규칙을 가지고 있는지 확인해야 한다 쿼리스트링을 없애는것이 답이 아니다
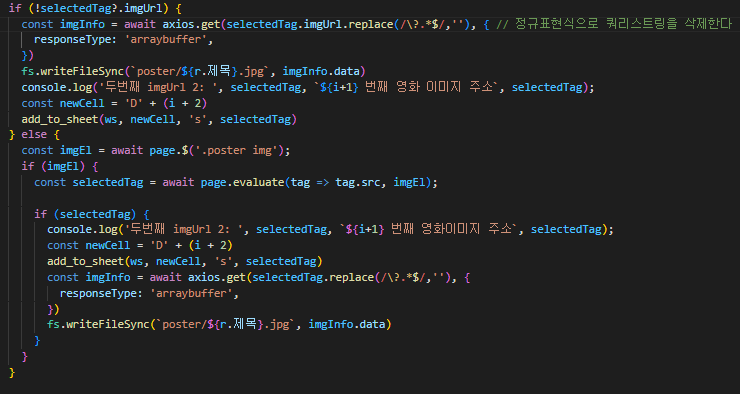
if (!selectedTag?.imgUrl) {
const imgInfo = await axios.get(selectedTag.imgUrl.replace(/\?.*$/,''), { // 정규표현식으로 쿼리스트링을 삭제한다
responseType: 'arraybuffer',
})
fs.writeFileSync(`poster/${r.제목}.jpg`, imgInfo.data)
console.log('두번째 imgUrl 2: ', selectedTag, `${i+1} 번째 영화 이미지 주소`, selectedTag);
const newCell = 'D' + (i + 2)
add_to_sheet(ws, newCell, 's', selectedTag)
} else {
const imgEl = await page.$('.poster img');
if (imgEl) {
const selectedTag = await page.evaluate(tag => tag.src, imgEl);
if (selectedTag) {
console.log('두번째 imgUrl 2: ', selectedTag, `${i+1} 번째 영화이미지 주소`, selectedTag);
const newCell = 'D' + (i + 2)
add_to_sheet(ws, newCell, 's', selectedTag)
const imgInfo = await axios.get(selectedTag.replace(/\?.*$/,''), {
responseType: 'arraybuffer',
})
fs.writeFileSync(`poster/${r.제목}.jpg`, imgInfo.data)
}
}
}
const setTime = await page.evaluate(async() => {
const timeList = await [3975, 4547, 5231, 6397, 7894, 3394, 4206, 5147, 6932, 7430, 3561, 4896, 5877, 6407, 7133];
const randomTime = await timeList[Math.floor(Math.random() * timeList.length)]
await new Promise(r => setTimeout(r, randomTime))
return randomTime
})
console.log('setTime', setTime)
}
await page.close();
await browser.close();
xlsx.writeFile(workbook, 'xlsx/xlsxRsult.xlsx')
} catch (e) {
console.error(e)
}
}
crawler();
라이브러리를 우선 불러옵니다
세팅방법은 이전 포스팅을 참고해주시길 바랍니다
여러 개가 있으니 한번 확인해보세요!
라이브러리 불러오는 것은 그렇게 어려운 것이 없으니
설명은 생략하겠습니다
workbook.Sheets.Sheet1의 의미는
제 엑셀 파일의 Sheet의 명이 Sheet1입니다
그래서 Sheet1의 데이터를 받아오게 됩니다
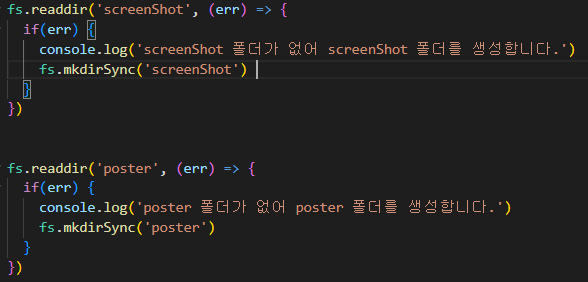
이미지를 저장할 폴더가 있는지 없는지 체크해서 폴더를 생성합니다
fs.readdir은 비동기로 이벤트 루프 속에서 작동하기 때문에 밑에 crawler함수와는 관계가 없습니다
또 한, fs함수 중 Sync를 사용하면 안 된다고 알고 계시겠지만
프로그램이 처음 시작될 때 한 번만 실행할 함수라면 Sncy함수를 사용해도 무관합니다
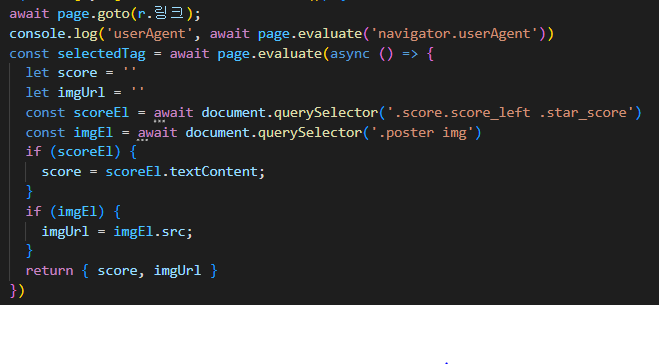
아래의 코드처럼 puppeteer의 launch()로 실행 준비를 하고
newPage()로 브라우저를 띄우게 됩니다
이때 setUserAgent()를 사용해서 나의 Agent정보를 지정할 수 있습니다
이 정보 값은 navigator.userAgent를 개발자 모드에서 콘솔 창에 적게 되면 노출되니 참고하세요
ws에 sheet1의 데이터를 가져오며 형식이 들어있기 때문에
add_to_sheet()를 사용해서
엑셀 파일의 평점과, 이미지 주소를 먼저 적습니다

add_to_sheet()의 코드는 아래와 같습니다
설명은 생략하며 한번 분석해보시길 바랍니다!!
const xlsx = require('xlsx');
function range_add_cell(range, cell) {
var rng = xlsx.utils.decode_range(range);
var c = typeof cell === 'string' ? xlsx.utils.decode_cell(cell) : cell;
if (rng.s.r > c.r) rng.s.r = c.r;
if (rng.s.c > c.c) rng.s.c = c.c;
if (rng.e.r < c.r) rng.e.r = c.r;
if (rng.e.c < c.c) rng.e.c = c.c;
return xlsx.utils.encode_range(rng);
}
module.exports = function add_to_sheet(sheet, cell, type, raw) {
sheet['!ref'] = range_add_cell(sheet['!ref'], cell);
sheet[cell] = { t: type, v: raw };
};
page.goto로 페이지 이동이 가능합니다
그리고 태그 접근을 하려면 두 가지 방법이 있습니다
우선 첫 번째 방법은 evaluate()에서 document접근이 가능하기에
querySelector()를 사용해서 태그에 접근해서 값을 가져옵니다
그 값들은 비구조화 할당으로 한 번에 객체로 return 합니다
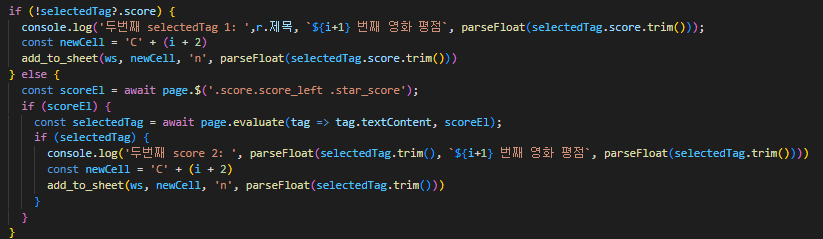
위에서 받아온 값에서 score값이 있으면
바로 엑셀에 값을 적용합니다
두 번째 매개변수는 엑셀의 어디 부분에 값을 넣을지 지정하는 것입니다
세 번째 매개변수는 데이터의 자료형을 지정하는 것입니다
그래서 저는 C2부터 시작하며, 'n' 즉 number를 넣겠다고 지정한 것입니다
그리고 score값이 없으면
다시 두 번째 방법으로 받는 것을 적용해보았습니다
이 방법은 page.$()를 활용해서 태그에 접근하는 element 값을 가져옵니다
그다음 evaluate() 함수를 사용해서 값을 가져와 할당합니다
이미지를 받기 위해서는 우선 axios.get으로 이미지 주소를 값으로 요청을 합니다
responseType은 arraybuffer로 설정합니다
이미지 주소로 요청받은 데이터는 버퍼이며,
이 버퍼가 연속적으로 들어가 있는 자료구조가 arraybuffer입니다
그리고 엑셀에 이미지 링크 주소를 입력하고
이미지를 다운로드하여. jpg로 내 컴퓨터의 poster폴더에 저장합니다
크롤링 로봇으로 보이지 않기 위해
여러 가지 타임을 배열로 넣어 setTime을 실행합니다
그래서 다음 페이지 작업의 시간 간격을 두어 진행하게 됩니다

마지막 브라우저를 닫고
엑셀 파일에 데이터를 넣은 정보 값을 할당하여
파일로 만들어서 종료합니다
콘솔 창에 노출된 여러 정보 값을 확인할 수 있으며
진행상황에서 확인된 setTime과 score값 등을 확인할 수 있습니다

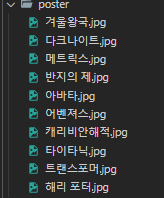
아래와 같이 파일 구조와
poster폴더에 jpg 파일이 생성된 것이 확인할 수 있습니다
엑셀 파일에 입력된 이미지 주소를 확인할 수 있습니다

이렇게 엑셀 쓰기와 웹 크롤링 작업을 알아보았습니다
여러 작업이 동반된 개발이라 개인적인 프로젝트를 해도 유용하다고 생각합니다
이것으로 무엇을 해볼까 생각 중입니다
아무튼 이렇게 공부를 끝내겠습니다
앞으로도 계속 공부를 해야 하는 입장에서 힘들겠지만
파이팅 하시길 바랍니다
그럼 다음 포스팅도 많은 관심 부탁드립니다
'IT_Web > Nodejs' 카테고리의 다른 글
| 웹 크롤링 인피니트 스크롤링 조작하여 이미지 다운받고 파일만들기 (0) | 2022.08.27 |
|---|---|
| 웹 크롤링 퍼펫티어 활용하여 스크린샷 이미지 폴더에 저장하기 (2) | 2022.08.26 |
| nodejs 웹 크롤링을 Puppeteer 및 Promise 활용 완벽 파헤치고 CSV파일 쓰기 (0) | 2022.08.20 |
| 웹 크롤링 axios 및 cheerio 활용해서 간단하게 적용해보기 (0) | 2022.08.18 |
| node.js로 엑셀 및 CSV 파일 데이터 간단하게 가져오기 (0) | 2022.08.17 |