
이전 포스팅에서 웹 크롤링을 하여 스크린샷을 찍는 방법에 대해
풀 스크린과 어느 특정 영역, 또는 화면 전체 이렇게 3가지 방법으로
스크린샷 찍는 방법을 알아보았습니다
웹크롤링할 때 화면 비율을 적용하는 등 여러가지를 알아보았습니다
더 자세히 알고 싶으시다면 아래 링크를 클릭해 주시길 바랍니다
그리고 이전 포스팅에서 설명한 세팅과 엑셀파일 쓰기, 읽기 등
자세한 설명은 생략할 수 있으니 참고 하시길 바랍니다
2022.08.26 - [IT_Web/Nodejs] - 웹 크롤링 퍼펫티어 활용하여 스크린샷 이미지 폴더에 저장하기
웹 크롤링 퍼펫티어 활용하여 스크린샷 이미지 폴더에 저장하기
이전 포스팅 웹크롤링 이미지 다운로드 적용하기 퍼펫티어를 활용해 웹 크롤링을 하여 이미지 다운로드를 적용해보았다 navigator.userAgent에 대한 속성 값도 변경해보고, 이미지를 웹에서 다운받
tantangerine.tistory.com
인피니트 스크롤링이란?
먼저 인피니트 스크롤링이란 무엇일까요?
이 효과는 페이스북, 인스타그램 등 많은 사이트에서 사용을 하고 있는 방법입니다
사용자가 클릭을 하지않고 컨텐츠에 계속 집중할 수 있도록
스크롤링만으로 사용자에게 컨텐츠가 무한 노출하여
사이트 이탈율을 방지하는 효과가 있습니다
그래서 조회하는 버튼형식이 아닌 스크롤을 조작해서
어느 위치에 오면 컨텐츠를 조회하는 것입니다
그래서 이제는 웹크롤링할 때 스크롤을 조작해서
이미지를 다운받는 방법 구현하려합니다
하지만 인피니트 스크롤링을 구현할 경우에는
싱글 페이지 어플리케이션을 활용하는 웹 사이트가 대부분입니다
그리고 리액트를 사용했다면 클라이언트 사이드 랜더링을 사용하기 때문에
웹크롤링이 쉽지않습니다
그래서 이런 경우에는 puppeteer를 사용하면 웹크롤링이 수월해집니다
그리고 웹 크롤링하기 적당한 웹 사이트인지 판단하기위해
postman을 사용하여 개발하기 이전에 어느정도 판단이 가능합니다
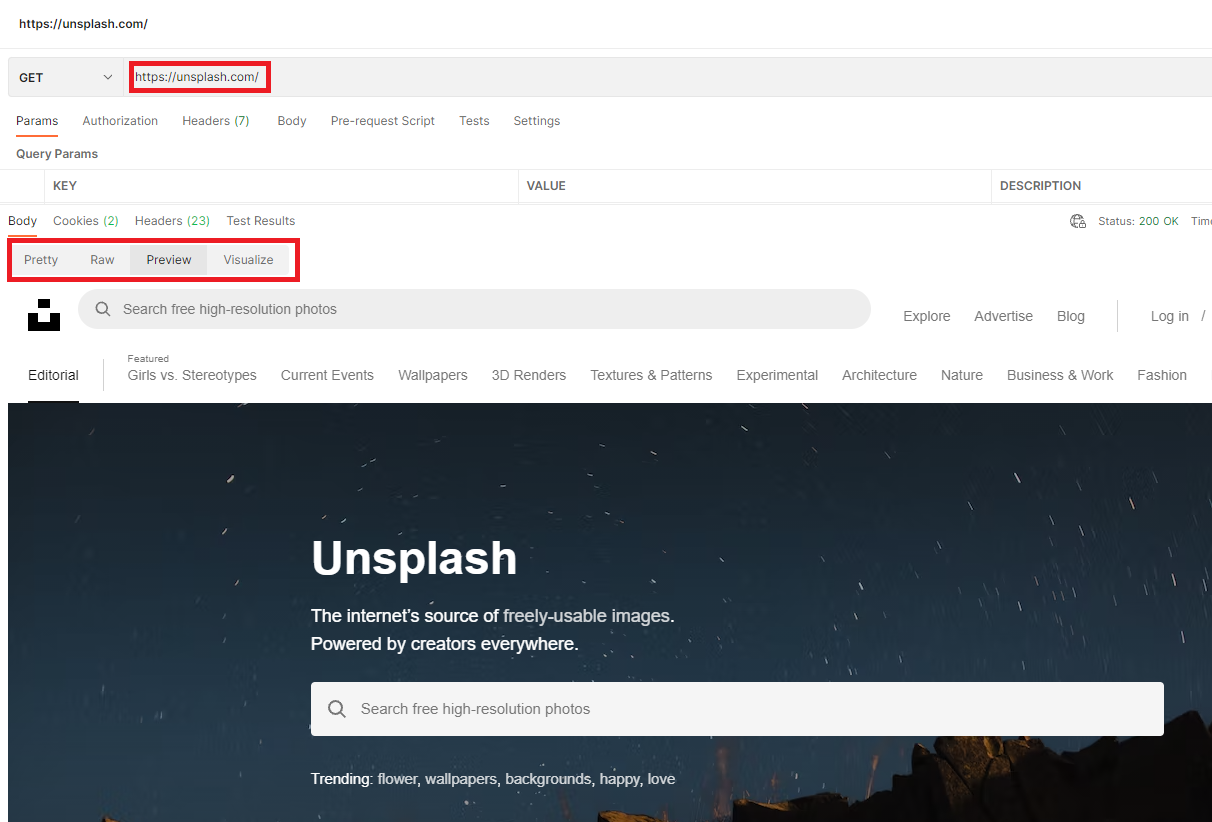
아래의 빨간영역을 보시면 웹크롤링할 사이트로 요청을 보내면
html코드, 그리고 웹 크롤링하려는 사이트의 미리보기가 가능합니다
그래서 이미지를 보거나 코드를 보면서 선택자 접근이 얼마나 가능한지도 판단해서
웹크롤링을 시작할 수 있습니다
스크롤조작 해서 이미지 다운받기
웹 스크롤 대상 웹 사이트는 unsplash.com 입니다
이미지 다운받기 이전에
태그에 접근 하는 방법을 먼저 알아보고 코드 분석에 들어가겠습니다
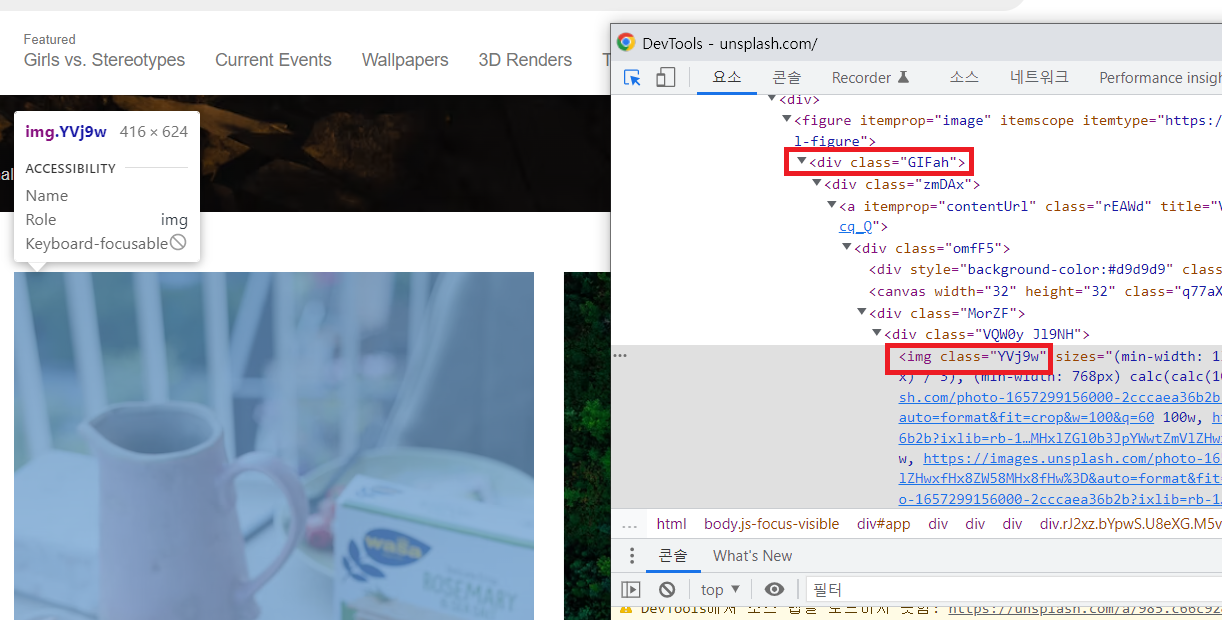
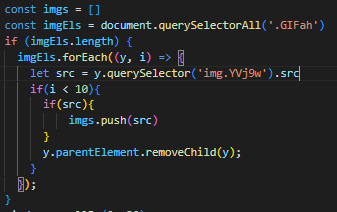
지금 현재 위에서 보시면 두개의 태그가 있습니다
<div class="GIFah">와 <img class="YV19w"> 두 개의 태그를 볼 수 있습니다
그래서 접근이 가능한지 아니면 필요없는 태그가 붙어서 오는지 선택자를 사용해서 미리 태그에 접근을 해봅니다
아래의 이미지와 같이 태그 접근이 가능한 것을 확인할 수 있습니다
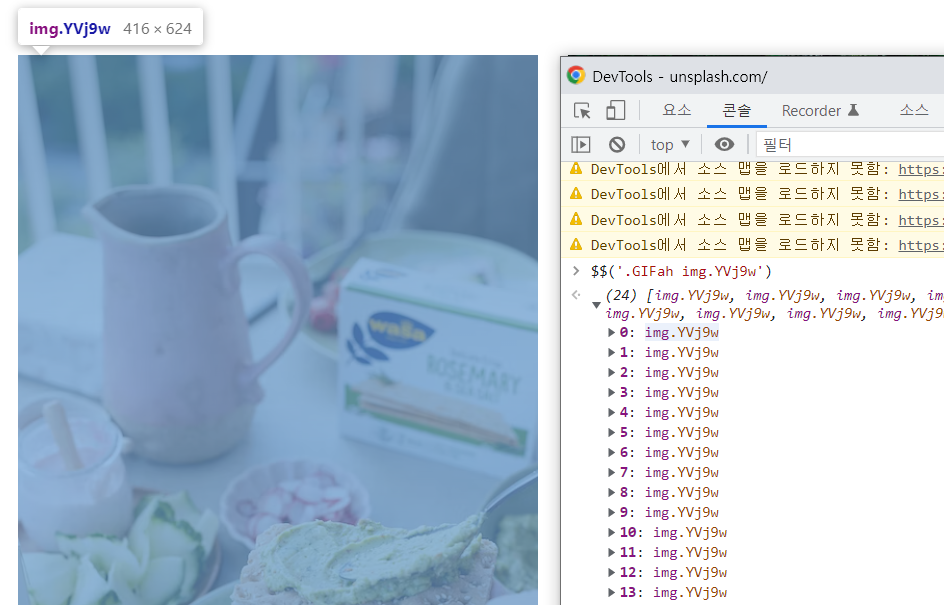
그럼 이제 아래의 코드를 천천히 분석해보시길 바랍니다
아래에 코드를 보시면
브라우저와 페이지 영역을 설정하여 해상도를 높입니다
그리고 querySelectorALL을 활용해서 이미지의 부모 엘리먼트를 태그를 가져옵니다
그리고 태그로 forEach를 사용하여 자식 img태그에 접근하여
src에 접근하여 이미지 주소를 가져와 이미지 다운받는 것까지 구현하였습니다
상세한 설명은 아래에서 하겠습니다
const axios = require('axios')
const fs = require('fs');
const puppeteer = require('puppeteer');
fs.readdir('imges', (err) => {
if(err) {
console.log('imges 폴더가 없어 imges 폴더를 생성합니다.')
fs.mkdirSync('imges')
}
})
const crawler = async () => {
try {
const browser = await puppeteer.launch({
headless: false,
args:['--window-size=1920,1080']
});
const page = await browser.newPage();
await page.setViewport({
width: 1920,
height:1080,
});
await page.goto('https://unsplash.com')
let result = []
while(result.length < 10) {
const srcs = await page.evaluate(() => {
window.scrollBy(0, 0)
const imgs = []
const imgEls = document.querySelectorAll('.GIFah')
if (imgEls.length) {
imgEls.forEach((y, i) => {
let src = y.querySelector('img.YVj9w').src
if(i < 10){
if(src){
imgs.push(src)
}
y.parentElement.removeChild(y);
}
});
}
window.scrollBy(0, 30)
return imgs
});
result = result.concat(srcs)
await page.waitForSelector('.GIFah')
console.log('result', result.length, result)
}
result.forEach(async(imgUrl, i) => {
if (imgUrl) {
const imgInfo = await axios.get(imgUrl.replace(/\?.*$/,''), {
responseType: 'arraybuffer',
})
fs.writeFileSync(`imges/${new Date().valueOf()}.jpeg`, imgInfo.data)
}
})
await page.close();
await browser.close();
} catch (e) {
console.error(e)
}
}
crawler();
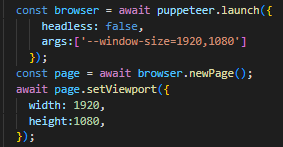
아래의 같이 해상도를 크게 설정합니다
스크롤을 조작하는데 너무 해상도가 작으면
스크롤 위치가 너무 많이 이동을 하게되면
스크롤링으로 다음 컨텐츠 조회가 잘 되지않는 현상이 있으니 참고하시길 바랍니다
아래에서 선택자를 사용해서 태그에 접근합니다
그리고 그 태그로 이미지태그를 접근하여 이미지를 다운받습니다
그리고 중요한것은 현재 가지고 있는 태그의 부모 태그에 접근해서 모든 하위 태그를 삭제합니다
그렇게 되면 처음 가져온 image 주소를 저장하고나서 필요없게 된 태그를 삭제하여
다음 스크롤링 해서 가져온 이미지 관련 태그만 접근할 수 있다는 장점이 있습니다
while문으로 특정 조건이 만족할 때까지 무한 루프가 실행됩니다
그리고 concat을 해서 가져온 이미지 주소를
최종 결과 변수에 저장을 합니다
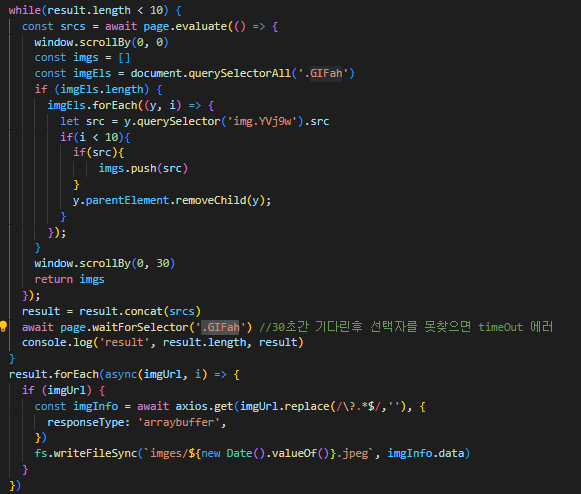
그리고 forEach로 파일을 만들어서 확인할 수있습니다
window.scrollBy()로 스크롤릉 내리는 효과를 주어 다음 컨텐츠를 조회하게 합니다
그리고 최종 결과 변수 값에 배열이 계속저장되어
결국에는 특정조건이 맞지 않게되면
무한 루프에서 나와 파일을 만들고
브라우저 및 페이지를 종료합니다
오늘은 여기까지입니다
웹 크롤링을 사이드 프로젝트를 하게되면서 여러가지 응용할 수 있을것같습니다
그래서 조금 기대도 되고 다음에 사이드 프로젝트를 하는것을
포스팅해서 올리겠습니다
이렇게 공부를 하면서 사이드 프로젝트를 만들어가는 과정에
흥미를 붙여서 계속 공부하려는 의지를 붙여주는게 정말 중요한 것같습니다
우리는 아직 너무많은 이야기들이 남았으니까요
솔직히 개발자가들의 공부가 어디가 끝인지도 잘모르겠네요
그러니 흥미 잃지마시고 끝까지 파이팅 하시길바랍니다
우리 IT 대모험은 끝나지 않았으니까요!!
'IT_Web > Nodejs' 카테고리의 다른 글
| 웹 크롤링 puppeteer 활용 및 keyboard press 함수로 키보드 코드 입력하기 (0) | 2022.08.30 |
|---|---|
| 웹 크롤링 로그인, 로그아웃 그리고 waitForResponse 응답대기 활용하기 및 태그찾기, 태그 값 할당 (0) | 2022.08.29 |
| 웹 크롤링 퍼펫티어 활용하여 스크린샷 이미지 폴더에 저장하기 (2) | 2022.08.26 |
| 웹크롤링 이미지 다운로드 및 puppeteer 활용해 이미지 주소 엑셀에 입력하기 (2) | 2022.08.24 |
| nodejs 웹 크롤링을 Puppeteer 및 Promise 활용 완벽 파헤치고 CSV파일 쓰기 (0) | 2022.08.20 |