
이전 포스팅에 대하여
이전 포스팅에서는 간단하게 웹 크롤링을 하는 방법을 알아보았습니다
axios와 cheerio를 사용해서 웹 크롤링을 해보았습니다
하지만 axios는 한계가 있습니다
싱글 페이지로 만들어진 웹페이지는 axios로 정보를 받아올 수 없다는 점이
그 한계입니다 그래서 좀 더 강력한 라이브러리를 사용하여 웹크롤링을 하려 합니다
그래도 cheerio는 간단한 웹페이지를 크롤링할 때에는
라이브러리가 가볍기 때문에 상황에 맞게 사용한다면 좋을 듯합니다
더 자세한 사항은 아래의 링크를 클릭해주시길 바랍니다
2022.08.18 - [IT_Web/Nodejs] - 웹 크롤링 axios 및 cheerio 활용해서 간단하게 적용해보기
웹 크롤링 axios 및 cheerio 활용해서 간단하게 적용해보기
이전 포스팅에서는 엑셀과 CSV 파일에 저장되어 있는 데이터를 불러오는 것을 알아보았습니다 다른 타 부서나 프로젝트진행에 필요한 파일들이 저장된 데이터를 가져오기 위해 엑셀 및 CSV 파일
tantangerine.tistory.com
지금 웹 크롤링 관련 포스팅이 이어지다 보니
기존 소스코드를 사용하는 경우가 많으니 이전 포스팅에서
어떻게 진행되었는지 꼭 확인하시고 오시길 바랍니다
그럼 CSV 파일의 정보를 가져와서
웹크롤링을 하도록 하겠습니다
CSV 파일에는 영화 제목과 url 링크 주소가 함께 있습니다
파일 구조와 처음 세팅이 궁금하시다면
아래의 링크를 확인해주세요
2022.08.17 - [IT_Web/Nodejs] - node.js로 엑셀 및 CSV 파일 데이터 간단하게 가져오기
node.js로 엑셀 및 CSV 파일 데이터 간단하게 가져오기
node.js 관련은 처음 소개하는 것 같습니다 다음에 node.js로 서버 구축하는 것도 알아볼 테니 많은 관심 부탁드립니다 우선 node 다운로드 링크 주소는 사이드바에 생성해 놓을 테니 확인해 보시길
tantangerine.tistory.com
Puppeteer 및 Promise 활용해서 웹 크롤링하기
puppeteer의 공식문서는 아래의 링크를 확인해보세요!!
https://github.com/puppeteer/puppeteer/blob/v16.2.0/docs
GitHub - puppeteer/puppeteer: Headless Chrome Node.js API
Headless Chrome Node.js API. Contribute to puppeteer/puppeteer development by creating an account on GitHub.
github.com
이제 본론으로 들어가서
웹 크롤링을 시작해 봅시다
먼저 아래와 같이 라이브러리를 설치합니다
npm i puppeteer
아래와 같이 코드를 작성합니다
새로운 함수들과 부가적인 설명이 필요할 것 같습니다
const puppeteer = require('puppeteer');
const crawler = async () => {
const browser = await puppeteer.launch({headless: false}); // 웹브라우저 노출여부
const page1 = await browser.newPage() // 페이지 노출하기
const page2 = await browser.newPage() // 탭으로 페이지가 여러개 노출할 수 있습니다
const page3 = await browser.newPage()
await page1.goto('https://naver.com'), //페이지 이동
await page2.goto('https://google.com'),
await page3.goto('https://www.daum.net')
await page1.evaluate(async() => { // 그리고 잠시대기
await new Promise(r => setTimeout(r, 3000))
}),
await page2.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
}),
await page3.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
})
await page1.goto('https://n.news.naver.com/mnews/ranking/article/437/0000310583?ntype=RANKING&sid=001'),
await page2.goto('https://newslibrary.naver.com/search/searchByDate.naver'),
await page3.goto('https://google.com')
await page1.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
}),
await page2.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
}),
await page3.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
})
await page1.close(), // 탭 페이지 닫기
await page2.close(),
await page3.close()
await browser.close(); // 브라우저 닫기
}
crawler();
웹 크롤링은 일반적으로 비동기를 사용해야 합니다
그 이유는 브라우저를 띄우고 로그인을 하고 그런 일괄된 작업들이 진행되면서 순차적으로 작업을
진행해야 작업이 꼬이지 않기 때문입니다
예로 브라우저를 띄우고 로그인을 할 경우 브라우저가 노출이 되지도 않았는데
로그인을 하려고 한다면
에러를 발생하기 때문입니다
그래서 puppeteer를 사용하면서 얼마나 비동기를 자유자재로 사용하는지가
가중 중요한 핵심이라고 할 수 있습니다
이제 코드적인 설명을 해보겠습니다
아래와 같이 launch() 함수에 headless: false가 적용되어있습니다
웹브라우저를 노출해서 웹 크롤링하는 작업을 볼 수 있습니다
개발 초기에는 false로 적용해서 개발을 하면서
수정사항을 고쳐나갈 것입니다

실제 프로젝트를 진행한다면 false값에
아래와 같이 적용해야 할 것입니다
그럼 env의 상태로 개발, 운영을 구분하여 웹페이지를 노출하게 될 것입니다

그리고 페이지를 이동하고 나서
잠시 대기하는 시간을 갖습니다
예전에 puppeteer.waitFor을 사용하였습니다
하지만 버전이 올라가면서 해당 함수가 삭제되어서
아래와 같이 구현할 수 있습니다
태그에 접근할 정보가 있다면
evaluate()함수는 tag의 value값에 접근이 가능합니다
하지만 콜백함수를 활용해서 비동기로 setTimeout함수를 사용해서
함수 실행을 딜레이 합니다
그리고 잠시 대기하는 시간이 왜 필요한지도 궁금하실 수 있습니다
그 이유는 자동으로 웹크롤링을 진행하게 되면
그 속도가 엄청 빠르다는 것입니다
그럼 웹페이지를 운영하는 입장에서는
비정상적인 동작이라고 생각하기 때문에
우리에게 제재를 줄 수 있습니다
비정상적인 방법이라는 인식을 피하기 위함입니다

이렇게 간단한 함수들을 정리해보았습니다
하지만 지금 이 방법은 순차적으로 진행하다 보니
다소 시간이 소요됩니다
만약 더 많은 작업을 한다면 소요되는 시간은 더 클 것이라고 생각합니다
그래서 이제 프로미스를 적용해서 한방에 요청하고
순차적으로 가 아닌 먼저 도착한 순서대로 진행하여
작업 시간을 단축해보도록 하겠습니다
Promise.all을 활용해서 웹크롤링 시간 단축 하기
아래와 같이 코드를 변경합니다
Promise.all을 사용한 것이 보이시나요?
함수마다 Promise.all을 적용해서 동시 작업을 진행합니다
이때 비동기이지만 한 번에 작업할 때마다 동시에 한다는 점입니다
그래서 전체적으로 볼 때는 비동기라는 것을 인지해 주세요
부가적인 설명은 필요가 없을 것 같습니다
그럼 이제는 CSV 파일을 읽어서 그 정보를 바탕으로 웹 크롤링을 해보겠습니다
const puppeteer = require('puppeteer');
const crawler = async () => {
const browser = await puppeteer.launch({headless: process.env.NODE_ENV === 'production'});
const [page1, page2, page3] = await Promise.all([
browser.newPage(),
browser.newPage(),
browser.newPage()
])
await Promise.all([
page1.goto('https://naver.com'),
page2.goto('https://google.com'),
page3.goto('https://www.daum.net')
]);
await Promise.all([
page1.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
}),
page2.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
}),
page3.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
})
]);
await Promise.all([
page1.goto('https://n.news.naver.com/mnews/ranking/article/437/0000310583?ntype=RANKING&sid=001'),
page2.goto('https://newslibrary.naver.com/search/searchByDate.naver'),
page3.goto('https://google.com')
]);
await Promise.all([
page1.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
}),
page2.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
}),
page3.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
})
]);
await Promise.all([
page1.close(),
page2.close(),
page3.close()
]);
await browser.close();
}
crawler();
CSV 파일을 읽어서 웹크롤링 시작하기
CSV 파일을 읽기 위해서는 라이브러리가 필요합니다
그리고 초기 세팅이 필요하겠지요
그것은 위에 링크를 걸어 두었던 것 기억하시지요?
그것을 참고하시길 바랍니다
아래와 같이 코드를 작성합니다
const parse = require('csv-parse/lib/sync');
const stringify = require('csv-stringify/lib/sync')
const fs = require('fs');
const puppeteer = require('puppeteer');
const csv = fs.readFileSync('csv/data.csv');
const records = parse(csv.toString('utf-8'))
const crawler = async () => {
const resultScore = []
try {
const browser = await puppeteer.launch({headless: false});
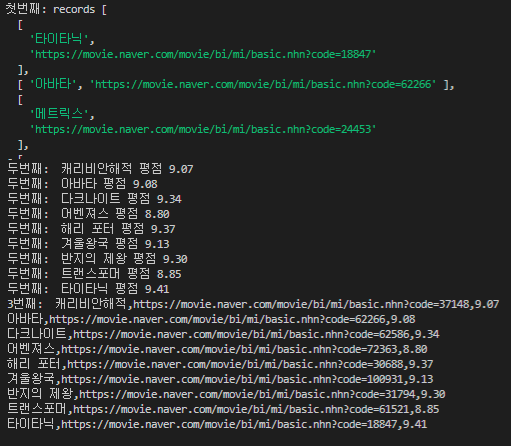
console.log('첫번째: records', records)
// Promise.all을 활용해서 csv에서 받아온 records를 모든 배열의 정보를 동시에작업을 진행합니다
await Promise.all(records.map(async (r, i) => {
const page = await browser.newPage();
await page.goto(r[1]);
const scoreEl = await page.$('.score.score_left .star_score');
if (scoreEl) {
const text = await page.evaluate(tag => tag.textContent, scoreEl);
if (text) {
console.log('두번째: ', r[0], '평점', text.trim());
resultScore.push([r[0], r[1], text.trim()])
// resultScore[i] = [r[0], r[1], text.trim()]
}
}
await page.evaluate(async() => {
await new Promise(r => setTimeout(r, 3000))
})
await page.close();
}));
await browser.close();
const str = stringify(resultScore);
console.log('3번째: ', str)
fs.writeFileSync('csv/result.csv', str);
} catch (e) {
console.error(e)
}
}
crawler();
위의 코드에서
Promise.all을 사용해서 recodes.map을 매개변수 사용해서
한 번에 작업을 진행합니다
그리고 콘솔 창에는 아래와 같이 확인되었습니다
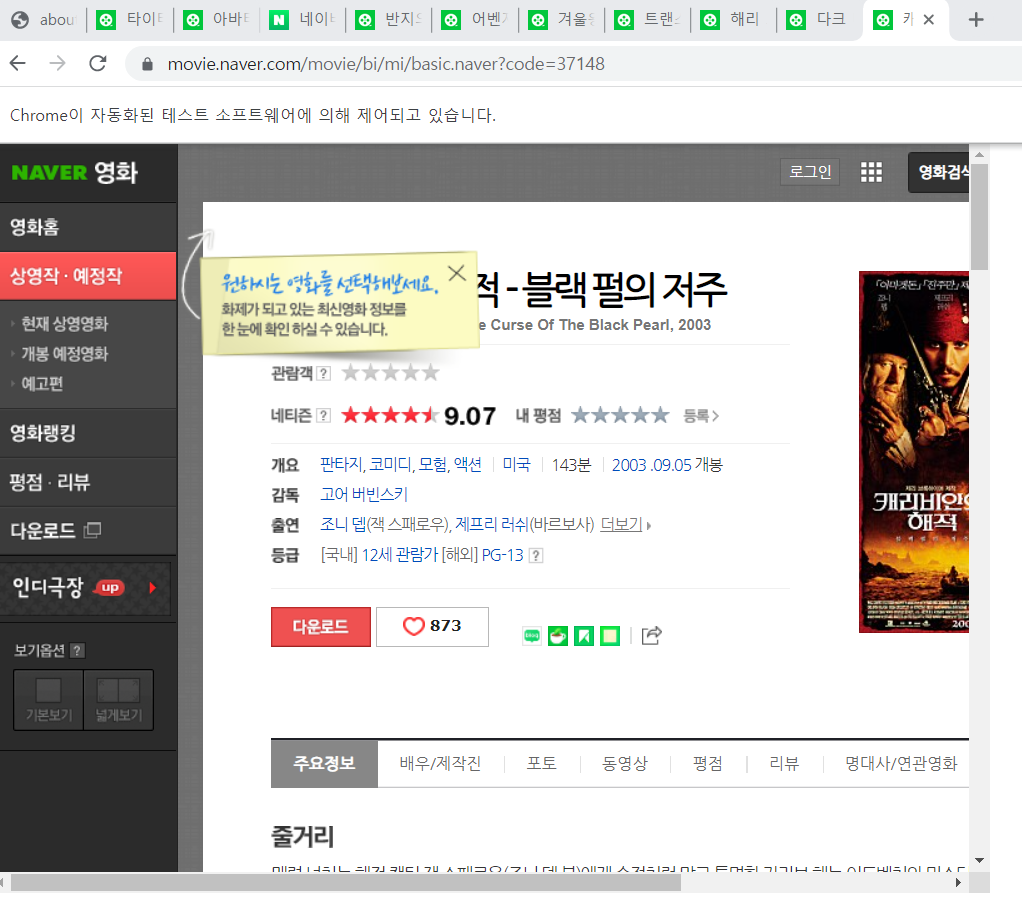
그래서 링크 주소를 활용해서 웹 크롤링을 시작합니다
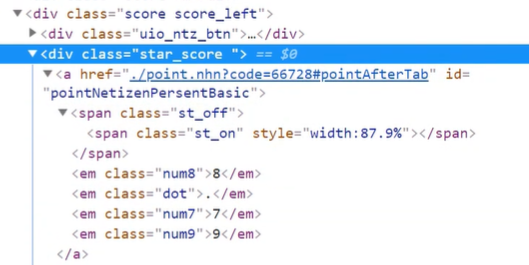
개발자 모드에서 아래와 같이 클래스명을 확인해서
데이터 값을 가져올 수 있는 위치를 확인합니다
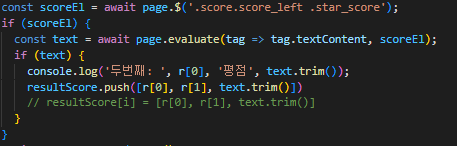
그래서 아래와 같이 클래스명을 기입해서
그 해당하는 textContent를 가져옵니다
이때 필요한 함수는 page.evaluate를 활용합니다
tag.textContent와 scoreEl를 return 받아
text 변수에 값이 있으면 push를 해서 최종 값을 저장합니다
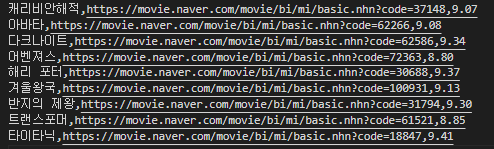
그리고 웹 크롤링해온 평점을 다시 CSV 파일에 넣어보도록 하겠습니다
먼저 라이브러리를 설치합니다
npm i csv-stringify
이전에 웹 스크롤링을 해서 저장된 데이터를
stringify함수를 사용해서 간단히 String으로 만듭니다
그래서 CSV 파일 형식으로 다른 이름으로 저장합니다

그 파일은 아래와 같습니다
하지만 문제가 있습니다
첫 번째 콘솔에 정렬된 순서와 저장되고 나서의 순서가
다르다는 것입니다
협업을 하다 보면 파일의 정보 순서가
정말 중요할 경우가 있습니다
위의 코드에서 주석 부분을 변경해서 i를 사용합니다
i는 인덱스 넘버가 저장되어있습니다
초기 배열의 저장된 순서가 i에 저장되어있어서
정렬순서가 보존될 수 있습니다

아래는 웹 크롤링할 경우에 노출되는 웹페이지입니다
10개가 동시에 열려있는 것이 보이시나요?
이렇게 웹 크롤링을 알아보았습니다
아직 여러 함수들을 사용하지 않고 정말 기본적인 것을 활용해서
웹크롤링을 해보았습니다
다음 포스팅에서는 더욱 심도 있는 기능으로 찾아뵙겠습니다
우리 IT의 대모험은 끝나지 않았습니다
끝나는(?) 그날까지 파이팅 하세요
'IT_Web > Nodejs' 카테고리의 다른 글
| 웹 크롤링 인피니트 스크롤링 조작하여 이미지 다운받고 파일만들기 (0) | 2022.08.27 |
|---|---|
| 웹 크롤링 퍼펫티어 활용하여 스크린샷 이미지 폴더에 저장하기 (2) | 2022.08.26 |
| 웹크롤링 이미지 다운로드 및 puppeteer 활용해 이미지 주소 엑셀에 입력하기 (2) | 2022.08.24 |
| 웹 크롤링 axios 및 cheerio 활용해서 간단하게 적용해보기 (0) | 2022.08.18 |
| node.js로 엑셀 및 CSV 파일 데이터 간단하게 가져오기 (0) | 2022.08.17 |