
이전 포스팅 웹크롤링 이미지 다운로드 적용하기
퍼펫티어를 활용해 웹 크롤링을 하여 이미지 다운로드를 적용해보았다
navigator.userAgent에 대한 속성 값도 변경해보고,
이미지를 웹에서 다운받아 드라이버에 저장하는 것과
받아온 이미지 링크 주소를 엑셀에도 넣어보았습니다
이번 포스팅도 이어지는 부분이 있으니 확인하시길 바랍니다
그리고 조금 더 상세한 부분은 아래의 링크를 확인해주세요
2022.08.24 - [IT_Web/Nodejs] - 웹크롤링 이미지 다운로드 및 puppeteer 활용해 이미지 주소 엑셀에 입력하기
웹크롤링 이미지 다운로드 및 puppeteer 활용해 이미지 주소 엑셀에 입력하기
이전 포스팅에서 웹크롤링 Puppeteer 및 Promise 활용 방법 Node.js로 웹 크롤링할 경우 Puppeteer를 사용하면 정말 편하게 개발을 할 수 있습니다 evaluate() 함수를 활용하여 잠시 대기시간을 갖거나, 선택
tantangerine.tistory.com
Puppeteer 활용해서 웹 사이트 스크린샷 이미지 저장하기
웹 크롤링을 하기위한 세팅은 이전 포스팅에서부터 이어지고 있으니
관심 있으신 분은 #웹 크롤링 태그를 클릭해서 확인해주시길 바랍니다
우선 아래의 코드를 작성합니다
launch(), setViewport(), page.screenshot()
함수에 대해서 알아보겠습니다
const fs = require('fs');
const puppeteer = require('puppeteer');
const xlsx = require('xlsx');
const workbook = xlsx.readFile('xlsx/data.xlsx');
const ws = workbook.Sheets.Sheet1;
const xlsxRecords = xlsx.utils.sheet_to_json(ws)
fs.readdir('screenShot', (err) => {
if(err) {
console.log('screenShot 폴더가 없어 screenShot 폴더를 생성합니다.')
fs.mkdirSync('screenShot')
}
})
const screenshotCrawler = async () => {
try {
const browser = await puppeteer.launch({
headless: false,
args:['--window-size=1920,1080']
});
console.log('첫번째: records', xlsxRecords)
const page = await browser.newPage();
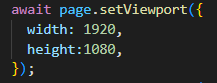
await page.setViewport({
width: 1920,
height:1080,
});
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36')
for(const [i, r] of xlsxRecords.entries()) {
await page.goto(r.링크);
await page.screenshot({
path: `screenShot/${r.제목}.png`, // 저장할 위치를 지정한다
fullPage: false, // 웹 페이지의 스크롤의 밑 전체 페이지를 스크린샷할 수 있다
clip: {
x: 100,
y: 100,
width: 300,
height: 300,
}// 왼쪽 상단 모서리 (x, y), 너비(width), 높이(height)
});// 그리고 fullPage와 clip은 같이 사용할 수 없다
const setTime = await page.evaluate(async() => {
const timeList = await [3975, 4547, 5231, 6397, 7894, 3394, 4206, 5147, 6932, 7430, 3561, 4896, 5877, 6407, 7133];
const randomTime = await timeList[Math.floor(Math.random() * timeList.length)]
await new Promise(r => setTimeout(r, randomTime))
return randomTime
})
console.log('setTime', setTime)
}
await page.close();
await browser.close();
} catch (e) {
console.error(e)
}
}
screenshotCrawler();
우선 초기에 해상도를 적용하지 않을 경우
아래와 같이 브라우저는 큰 화면이 아닌 반 정도인 것을 확인할 수 있습니다

아래의 코드에 보면 기존 코드에 args:['--window-size=1920,1080']를 추가하면 됩니다
그리고 1920, 1080은 자신의 모니터 해상도를 생각하시고 지정합시다

위의 코드를 적용하면 브라우저의 크기가 커진것을 확인할 수 있습니다
이제는 화면의 해상도를 키우면 브라우저만큼 크게 넓어질 것 같습니다

아래의 코드 setViewport() 함수를 적용합니다
브라우저 해상도와 맞게 값을 지정합니다
아래와 같이 화면이 해상도에 맞게 커지게 되었습니다
이제는 스크린샷을 찍는 코드를 적용하도록 하겠습니다
아래의 코드를 확인해봅시다
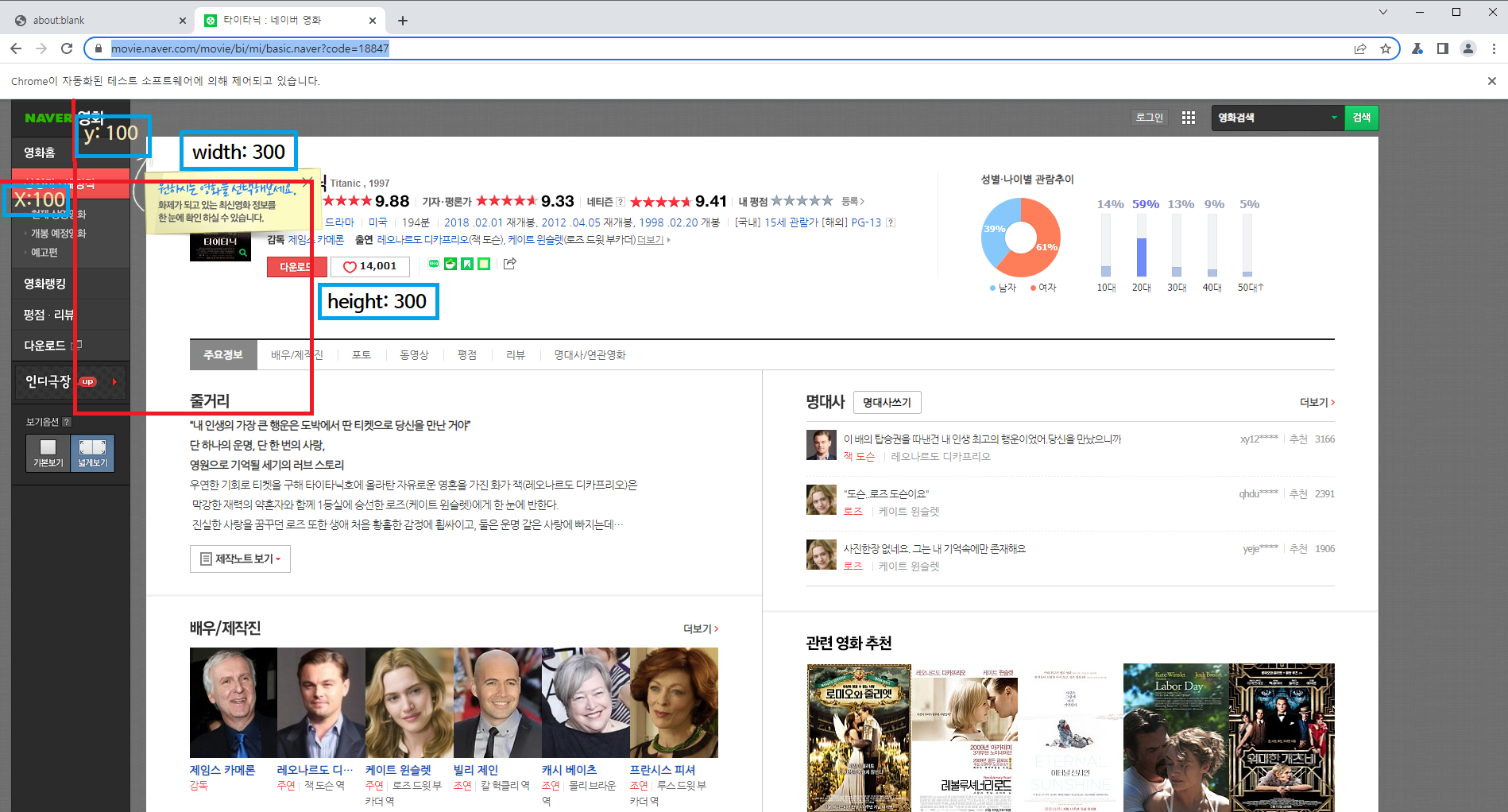
clip에 값을 지정하면 어느 한 영역을 스크린샷하여 찍을 수 있습니다
그 영역은 지정된 웹 페이지의 x, y축에서
width, height를 지정하여 사각형 영역을 만들어 스크린샷을 찍습니다

위와 같이 코드를 적용하면 아래와 같이
스크린샷을 찍게 되어 path의 위치에 저장하게 됩니다

아래의 전체 화면에 clip영역이 어떻게 지정되는지 확인이 가능합니다
이제는 fullPage를 true값을 주면 어떻게 스크린샷을 찍는지 확인해보겠습니다
fullPage값을 true로 지정하게 되면 아래와 같이 전체 화면을 찍게 됩니다
웹 페이지 전체를 찍는 것이니 유의해 주시길 바랍니다
그리고 한 가지 더 fullPage 값이 true일 경우 clip 값을 지정하면
에러가 발생하니 주의하시길 바랍니다

이렇게 웹크롤링에서 스크린샷을 찍어 보았습니다
간단하게 함수 3개로 구현하였습니다
웹크롤링 기능은 아직 많이 남았으니
조금만 참고 포스팅을 기대해주시고
힘내시길 바랍니다
아직 IT 대모험은 끝나지 않았으니까요
그럼 파이팅 하시고
다음 포스팅에서 뵙겠습니다
'IT_Web > Nodejs' 카테고리의 다른 글
| 웹 크롤링 로그인, 로그아웃 그리고 waitForResponse 응답대기 활용하기 및 태그찾기, 태그 값 할당 (0) | 2022.08.29 |
|---|---|
| 웹 크롤링 인피니트 스크롤링 조작하여 이미지 다운받고 파일만들기 (0) | 2022.08.27 |
| 웹크롤링 이미지 다운로드 및 puppeteer 활용해 이미지 주소 엑셀에 입력하기 (2) | 2022.08.24 |
| nodejs 웹 크롤링을 Puppeteer 및 Promise 활용 완벽 파헤치고 CSV파일 쓰기 (0) | 2022.08.20 |
| 웹 크롤링 axios 및 cheerio 활용해서 간단하게 적용해보기 (0) | 2022.08.18 |