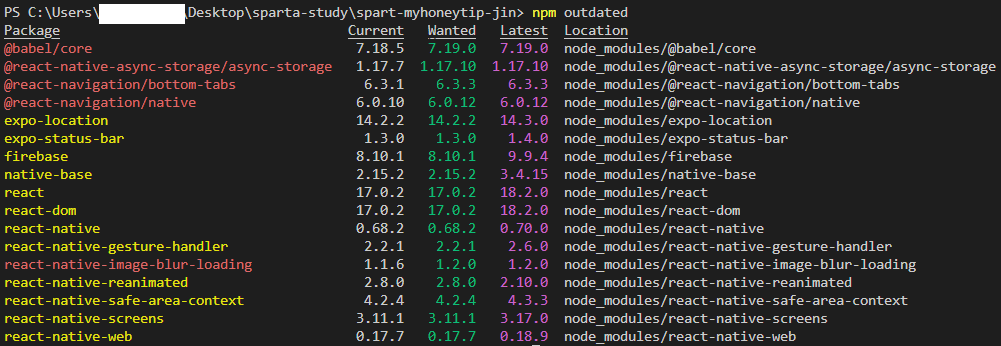
자바 개발자라면 API 호출은 일상 다반사입니다. 프론트엔드에서 주로 사용되는 API 호출 방식과 달리, 백엔드에서는 Java를 이용한 호출이 많이 이루어집니다. 특히 Apache HttpClient와 HttpURLConnection을 비교해볼 때, 각각의 장단점과 사용법을 알아보는 것이 중요합니다. 이 글에서는 두 라이브러리를 활용한 API 호출 방법을 자세히 설명하며, 왜 Apache HttpClient가 더 간결하고 효율적인지에 대해 탐구해보겠습니다.

HttpURLConnection을 이용한 API 호출
Java의 기본 라이브러리인 HttpURLConnection을 사용하면, 다음과 같은 방식으로 GET 요청을 보낼 수 있습니다.
HttpURLConnection을 이용한 기본 GET 요청 예제 코드
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpGetRequestExample {
public static void main(String[] args) {
try {
// 기본 URL
String baseUrl = "http://example.com/api";
// 파라미터 추가
String params = "?param1=value1¶m2=value2";
String urlString = baseUrl + params;
// URL 객체 생성
URL url = new URL(urlString);
// HttpURLConnection 객체 생성
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// 요청 방식 선택 (GET)
connection.setRequestMethod("GET");
// 요청 헤더 추가 (옵션)
connection.setRequestProperty("User-Agent", "Mozilla/5.0");
// 응답 코드 가져오기
int responseCode = connection.getResponseCode();
System.out.println("GET Response Code :: " + responseCode);
// 응답 코드가 200 OK인 경우, 응답 내용 읽기
if (responseCode == HttpURLConnection.HTTP_OK) {
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String inputLine;
StringBuffer response = new StringBuffer();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
in.close();
// 응답 내용 출력
System.out.println(response.toString());
} else {
System.out.println("GET request not worked");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Apache HttpClient의 등장
반면, Apache HttpClient 라이브러리를 사용하면, 코드가 훨씬 간결해집니다. Maven을 사용하는 프로젝트의 경우, 다음과 같이 의존성을 추가해야 합니다.
Apache HttpClient를 이용한 GET 방식은 다음과 같습니다.
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class HttpClientGetExample {
public static void main(String[] args) {
// HttpClient 객체 생성
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
// URIBuilder를 사용하여 URL 및 파라미터 구성
URIBuilder uriBuilder = new URIBuilder("http://example.com/api");
uriBuilder.addParameter("param1", "value1");
uriBuilder.addParameter("param2", "value2");
// HttpGet 객체 생성
HttpGet httpGet = new HttpGet(uriBuilder.build());
// 요청 헤더 추가 (옵션)
httpGet.addHeader("User-Agent", "Mozilla/5.0");
// 요청 실행 및 응답 받기
try (CloseableHttpResponse response = httpClient.execute(httpGet)) {
// 응답 본문을 String으로 변환
String result = EntityUtils.toString(response.getEntity());
// 결과 출력
System.out.println(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Apache HttpClient를 사용하면 URIBuilder를 통해 URL과 파라미터를 쉽게 구성할 수 있고, HttpGet 객체를 생성하여 요청을 보낼 수 있습니다. 이는 코드를 간결하게 만들 뿐만 아니라, 개발자가 HTTP 통신의 세부사항에 덜 집중할 수 있게 해줍니다.
POST 요청 방식 비교
POST 요청에 대해서도 비교해봅시다. HttpURLConnection을 사용할 경우, OutputStream을 통해 직접 데이터를 전송해야 합니다.
HttpURLConnection을 이용한 POST 요청 예제 코드
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Scanner;
public class PostExample {
public static void main(String[] args) {
String targetURL = "http://example.com/api/resource";
HttpURLConnection connection = null;
try {
// URL 객체 생성 및 연결 설정
URL url = new URL(targetURL);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json; charset=UTF-8");
connection.setDoOutput(true); // OutputStream을 사용하여 요청 본문에 데이터를 쓸 것임을 지정
// 요청 본문에 JSON 데이터 작성
String jsonInputString = "{\"name\": \"John\", \"age\": 30}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes("utf-8");
os.write(input, 0, input.length);
}
// 응답 받기 및 출력
try (Scanner scanner = new Scanner(connection.getInputStream())) {
while (scanner.hasNextLine()) {
System.out.println(scanner.nextLine());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (connection != null) {
connection.disconnect();
}
}
}
}
반면, Apache HttpClient를 사용하면, 객체를 JSON으로 변환하여 HttpPost 객체에 전달하는 방식으로 간결하게 처리할 수 있습니다.
Apache HttpClient를 이용한 POST 요청 예제 코드
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
public class JsonExample {
public static void main(String[] args) throws Exception {
// 객체 생성
MyObject myObject = new MyObject();
myObject.setName("John Doe");
myObject.setAge(30);
// 객체를 JSON으로 변환
ObjectMapper objectMapper = new ObjectMapper();
String json = objectMapper.writeValueAsString(myObject);
// HTTP POST 요청 설정
HttpPost post = new HttpPost("http://example.com/api");
StringEntity entity = new StringEntity(json);
post.setEntity(entity);
post.setHeader("Accept", "application/json");
post.setHeader("Content-type", "application/json");
// 요청 실행
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
httpClient.execute(post);
}
}
// 자바 객체 정의
public static class MyObject {
private String name;
private int age;
// getters and setters
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
}
}

마무리
이 글에서는 Java에서 API 호출을 위한 두 가지 방법, 즉 HttpURLConnection과 Apache HttpClient의 사용법을 비교해보았습니다. Apache HttpClient의 사용이 더 간결하고 유연하다는 것을 확인할 수 있었습니다.
Java 개발에 있어서 이러한 라이브러리의 선택과 활용은 프로젝트의 효율성을 크게 향상시킬 수 있습니다.
더 궁금한 점이 있으시다면 댓글로 질문해주세요. 감사합니다.
'IT_Web > Java' 카테고리의 다른 글
| Java 활용해서 기본 템플릿 양식 넣고 메일 보내기 (0) | 2022.09.07 |
|---|---|
| Java 엑셀 데이터 읽어오기 및 다중 insert 한방에 하기 (1) | 2022.08.05 |
| [Java] 다형적변수, final, abstract, 형변환 활용 (0) | 2020.06.20 |
| [Java] 접근제어자 public, static, 기타제어자 활용법 (0) | 2020.06.18 |
| [Java] 상속자, 은닉변수, super(), this의 활용 (0) | 2020.06.14 |